
Tabla de Contenidos
Introducción
Desde pequeño, las computadoras han ejercido una fascinación magnética sobre mí. Recuerdo perfectamente la primera vez que vi una en la oficina de mi madre, a los 11 años; en ese instante, supe exactamente a qué quería dedicar mi vida.
Aunque el destino me llevó por la senda de la infraestructura, en mi corazón nunca abandoné la idea de desarrollar aplicaciones. Si bien poseo bases sólidas de programación y me defiendo bien frente a la terminal, la falta de práctica diaria y de tiempo para profundizar me habían impedido, hasta ahora, producir software a nivel profesional.
Sin embargo, hoy el panorama es distinto. Con el auge de la Inteligencia Artificial, los LLM y la IA Generativa, se ha abierto un nuevo horizonte para perfiles como el mío: la posibilidad de materializar aplicaciones complejas sin necesidad de ser un experto en sintaxis profunda, apoyándonos en editores que potencian nuestra capacidad creativa.
El reto: AWS Community Day Bolivia 2025
Esta aventura comenzó con la organización del AWS Community Day Bolivia 2025. Este año, el honor de liderar el evento recayó en el AWS User Group Cochabamba, equipo del cual soy uno de los líderes. Organizar un encuentro de esta magnitud exige una coordinación impecable con los voluntarios y, aunque herramientas como Google Forms o Sheets son útiles, yo buscaba algo más: una solución integral diseñada a medida.
Mi visión era construir una plataforma que nos permitiera:
- Gestionar proyectos: Crear y administrar iniciativas específicas del evento.
- Registro dinámico: Permitir que los voluntarios se inscribieran directamente en los proyectos.
- Comunicación multicanal: Enviar avisos y actualizaciones de forma centralizada.
- Panel Administrativo: Un portal seguro para operaciones exclusivas de los líderes autorizados.
- Innovación tecnológica: Probar Kiro, el IDE actual de Amazon, y sus potentes capacidades de IA generativa.
- Legado comunitario: Crear un proyecto “por la comunidad y para la comunidad” que sirviera como caso de estudio real en nuestras charlas.
El camino es la recompensa
Aunque el desarrollo no llegó a finalizarse a tiempo para el Community Day, la experiencia fue reveladora. Este proceso enriqueció profundamente mis conocimientos sobre IA Generativa, arquitectura de aplicaciones y el ciclo de vida del desarrollo moderno. Pero, sobre todo, me permitió descubrir los tips & tricks de los agentes de IA y la delicada relación humano-máquina necesaria para obtener el resultado deseado.
Al momento de publicar este artículo, Kiro ha avanzado muchísimo. Varias de las limitaciones iniciales que encontré han sido mejoradas, especialmente en lo que respecta a la gestión de sesiones y memoria, consolidándose como la herramienta de vanguardia que deja atrás versiones anteriores.
El “Vibe Coding” no es broma
Debo confesar que fui muy ingenuo al principio. Confiaba casi ciegamente en lo que Kiro producía, ya que, al menos de entrada, generó la estructura inicial del sitio de forma correcta y sorprendentemente rápida. El proyecto arrancó con una propuesta de especificaciones (Spec) diseñada por el propio Kiro; en el prompt le pedí que generara un proyecto serverless de tres capas: AstroJS para el frontend, FastAPI para el backend y DynamoDB para la persistencia de datos.
Durante las primeras etapas, trabajaba con tres editores abiertos y desplegaba directamente desde mi local a la cuenta de AWS del grupo de usuarios. Sin embargo, llegó el momento de hacer las cosas bien y configurar el despliegue mediante un flujo de CI/CD (porque ya saben: “en casa de herrero, cuchillo de palo”). Para ello, decidí utilizar AWS CDK. Según mi experiencia, mantener y gestionar los archivos de estado (state) es una preocupación adicional que quería evitar, por lo que descarté Terraform y Pulumi desde el inicio.
Unificar todos los proyectos bajo la misma sesión
Al inicio de cada tarea (task), ingresaba un prompt para pulir los detalles que no me convencían o que no funcionaban correctamente. Fue aquí donde me topé con el primer escollo: tenía cuatro sesiones diferentes de Kiro que no compartían contexto entre sí.
Si durante el desarrollo del frontend Kiro detectaba un bloqueo en la API, la herramienta se quedaba “ciega” respecto al otro componente, obligándome a realizar constantes procesos de copy-paste para transferir datos de un entorno a otro. Para solucionar esto, decidí centralizar todo en una única sesión. Agrupé todos los repositorios en un directorio raíz para que Kiro pudiera navegar entre ellos con plena conciencia de la relación entre los componentes.
A continuación, comparto la estructura local que definí para lograr esa sincronía:
❯ tree -L 1 -a
.
├── .amazonq
├── .devbox
├── .envrc
├── .gitignore
├── .kiro
├── .python-version
├── .venv
├── README.md
├── devbox.json
├── devbox.lock
├── generated-diagrams
├── pyproject.toml
├── registry-api
├── registry-documentation
├── registry-frontend
├── registry-infrastructure
└── uv.lock
9 directories, 8 files
El lector notará que tengo Devbox configurado en el directorio raíz. Tomé esta decisión porque Kiro necesitaba ejecutar frecuentemente scripts en Python para sanitizar los repositorios, realizar búsquedas o ejecutar tareas de troubleshooting. Por ello, vi la necesidad de proveerle una cadena de dependencias aislada, evitando así la instalación de software innecesario en mi sistema operativo principal.
Sin embargo, en el mundo del desarrollo, apenas se resuelve un problema suele asomarse otro mucho peor.
Reglas claras: El arte de la convivencia
Esta fue la etapa más compleja y la que más tiempo demandó. Fue el periodo de alineación entre la IA y yo; el momento en el que descubrimos el carácter, los límites y hasta dónde podíamos tolerarnos el uno al otro. El lector quizás sea escéptico, pero tras haber trabajado en decenas de sesiones, puedo afirmar que cada una desarrolla una “personalidad” distinta. Existe una diferencia sutil, pero real: la velocidad con la que captan el contexto previo, el tono de la conversación y la iniciativa varían entre sesiones.
Para quienes aún no han experimentado con Kiro (o Amazon Q), hay aspectos fundamentales que deben tomarse muy en serio:
- La volatilidad de las sesiones: Las sesiones son temporales. Al alcanzar un límite de contexto, la sesión se reinicia, transfiriendo apenas un sumario muy reducido de lo acontecido. En este proceso se pueden perder detalles críticos, especialmente si la actividad previa fue intensa.
- La gestión de confianza: Al ejecutar herramientas, Kiro consulta si los comandos son seguros. Si respondes negativamente, no ejecutará nada; si aceptas, ejecutará todo sin pedir confirmaciones adicionales. Es un “todo o nada” que requiere vigilancia.
- Invisibilidad de la estructura Git: Kiro no comprende el concepto de “repositorio” de forma nativa. Ignora la existencia de commits, ramas o archivos en staging. Por ello, es vital ser quirúrgico: hay que indicarle exactamente qué archivo modificar y qué cambio realizar.
- Desconexión del ecosistema del proyecto: No asume automáticamente la existencia de archivos de configuración, dependencias o flujos de CI/CD. Para Kiro, cada archivo es una entidad aislada a menos que tú le proporciones el mapa completo.
Ignorar estas reglas tiene un costo alto: Kiro generará código que no funciona o que no se ajusta a tus objetivos. Lo más peligroso es que la herramienta siempre te asegurará con confianza que todo está bien, dejándote con una falsa sensación de éxito.
El punto de quiebre llegó durante una iteración en la que solicité un ajuste arquitectónico. Kiro malinterpretó la instrucción y alteró todo el proyecto: transformó una arquitectura Serverless en una basada en ECS y Aurora. Fue una experiencia frustrante, pero necesaria. En ese momento decidí establecer reglas de compromiso: creé un documento de “Primitivas de Arquitectura”. En él definí lineamientos estrictos sobre la estructura del proyecto, la gestión de repositorios y el comportamiento esperado al publicar cambios.
A partir de ese contrato, el proyecto se estabilizó. Avancé con una fluidez que antes parecía imposible y, gracias a ello, la versión beta se materializó mucho antes de lo previsto y ya se encuentra disponible en línea.
El Blueprint: Anatomía de una Arquitectura Eficiente
La arquitectura del proyecto puede verse en el siguiente diagrama:
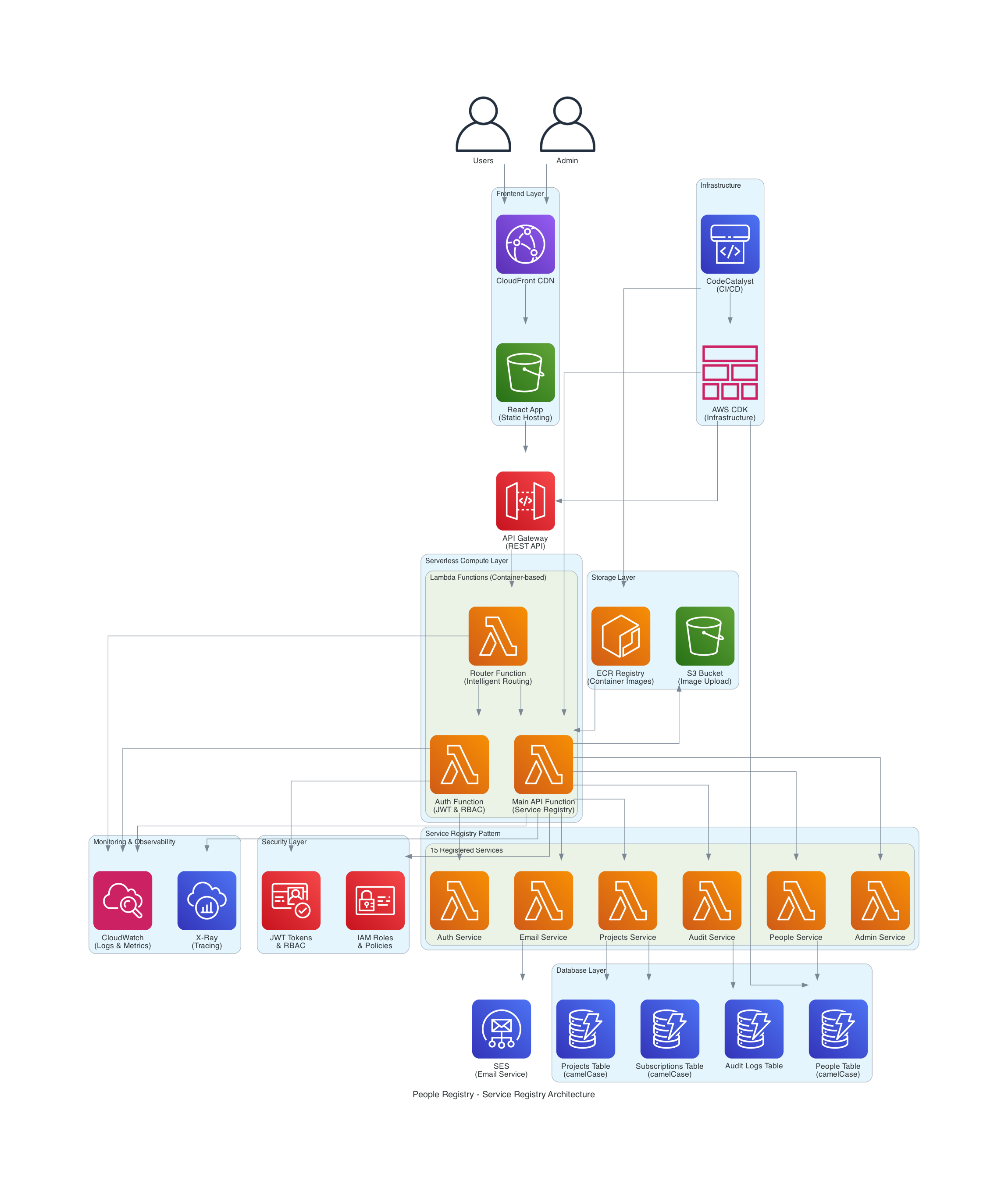
Para lograr los objetivos de costo y escalabilidad, diseñé una estructura modular dividida en capas lógicas. Así es como interactúan los componentes:
1. Capa de Acceso y Entrega (Edge & Auth)
Es la primera línea de contacto con el usuario, priorizando la seguridad y la velocidad.
- Amazon CloudFront: Actúa como CDN para distribuir el contenido con baja latencia global.
- Amazon Cognito: Funge como el Proveedor de Identidad (IDP), gestionando la autenticación y el ciclo de vida de usuarios y administradores.
2. Capa de Interfaz (API Gateway)
Separamos los planos de control para garantizar la seguridad de las operaciones sensibles.
- App API: Punto de entrada público para las funcionalidades de la aplicación.
- Admin API: Un Gateway dedicado y aislado para operaciones administrativas privilegiadas.
3. El Cerebro: Orquestación y Lógica Serverless
Aquí es donde reside la inteligencia del sistema, utilizando un enfoque de microservicios basados en eventos.
- AWS Step Functions: Orquesta flujos de trabajo complejos, asegurando que cada paso se ejecute en el orden correcto.
- Lambda Functions (Multi-purpose): Funciones especializadas que ejecutan la lógica de negocio, desde el enrutamiento (Route Manager) hasta el control de acceso (HBAC).
- Amazon ECR: Almacena las imágenes de contenedor que alimentan nuestras Lambdas, permitiendo entornos de ejecución consistentes.
- AWS CDK: El “pegamento” de todo el proyecto, permitiendo que esta infraestructura sea 100% reproducible mediante código.
4. Capa de Servicios y Registro Dinámico
El corazón del sistema utiliza el patrón Service Registry para evitar el acoplamiento rígido.
- Service Registry Pattern: Implementado mediante Lambdas que actúan como un directorio central, permitiendo el descubrimiento dinámico de servicios en tiempo de ejecución.
- Servicios Especializados: Módulos dedicados para búsquedas (Search Service), tareas programadas (Cron Service) y gestión de personas (People Service).
5. Persistencia y Comunicaciones (Data Layer)
Una combinación políglota para manejar diferentes tipos de datos con eficiencia.
- Amazon DynamoDB: Nuestra base NoSQL para alta velocidad en caché y gestión de casos.
- Amazon S3: Repositorio central para el almacenamiento de imágenes y objetos.
- Amazon SES: El motor de notificaciones para la comunicación directa con los voluntarios.
6. Capas Transversales: Seguridad y Observabilidad
Componentes que atraviesan toda la arquitectura para garantizar su salud y protección.
- Seguridad y Configuración: Uso intensivo de AWS Secrets Manager y Parameter Store para una gestión de secretos y políticas zero-trust.
- Observabilidad 360°: Implementación de Amazon CloudWatch para el rastreo (tracing), métricas de rendimiento y centralización de logs.
El Manifiesto del Proyecto: Patrones y Directrices
Para que la colaboración con la IA no terminara en el caos arquitectónico que mencioné antes, tuve que formalizar el conocimiento en dos pilares fundamentales. Estos documentos no solo guiaron a Kiro, sino que establecieron las bases de lo que considero un desarrollo moderno asistido.
1. Patrones de Arquitectura Empresarial (EAP)
No se trata solo de escribir código, sino de seguir principios que garanticen la evolución del sistema. Basándome en la documentación del Registry Project , implementamos tres reglas de oro:
- Aislamiento y Desacoplamiento: Cada servicio opera de forma autónoma. El uso del Service Registry no es opcional; es el mecanismo que permite que nuestra infraestructura crezca sin crear dependencias rígidas (spaghetti code).
- Diseño para la Resiliencia: Aplicamos el patrón de Sagas para manejar transacciones distribuidas en entornos serverless, asegurando que, si un paso falla, el sistema pueda recuperarse o compensar el error de forma automática.
- Seguridad por Diseño (Zero-Trust): Ningún componente confía en otro por defecto. Cada interacción requiere validación de identidad a través de Cognito y control de acceso basado en políticas estrictas.
2. Manual de Convivencia con la IA: El “AI Assistant Guidelines”
Aprender a hablar con un agente como Kiro requiere más que simples instrucciones; requiere un marco de trabajo. Estos son los puntos clave que rescatamos de nuestras guías de asistencia :
- Contexto Incremental: En lugar de lanzar prompts masivos, alimentamos a la IA con fragmentos de contexto específicos. Si Kiro conoce la estructura de la base de datos, pero no el flujo de autenticación, se lo recordamos explícitamente antes de pedirle un cambio en esa área.
- Validación Humana Obligatoria: La IA propone, el humano dispone. Establecimos que ningún despliegue ocurre sin una revisión manual de las diferencias (diffs) generadas. Esto evitó que el proyecto volviera a transformarse accidentalmente en una infraestructura costosa e innecesaria.
- Documentación Viva: Cada vez que la IA generaba una solución innovadora, esa lógica se documentaba inmediatamente. Así, la “memoria” del proyecto no dependía solo de la sesión actual de Kiro, sino de nuestro repositorio central de conocimiento.
El porqué de una arquitectura “Multi-Cloud-Ready” en un entorno AWS
Aunque el proyecto vive y respira en el ecosistema de Amazon Web Services, tomé una decisión estratégica desde el primer día: la arquitectura debía ser Multi-Cloud-Ready.
Muchos se preguntarán: ¿Para qué complicar el diseño si ya tenemos las herramientas de AWS? La respuesta reside en la soberanía técnica y el control de costos. Al implementar patrones como el Service Registry y utilizar Devbox para aislar entornos, evitamos el temido vendor lock-in (dependencia total de un solo proveedor).
Diseñar de esta manera nos obliga a separar la lógica de negocio de la infraestructura. Esto significa que, si mañana la comunidad decidiera migrar parte de la carga a otra plataforma o integrar servicios externos, el núcleo de nuestra aplicación no sufriría un trauma técnico. Es una arquitectura pensada para la libertad, donde AWS es nuestra elección por excelencia, pero no nuestra única posibilidad.
Conclusión
Este proyecto me permitió experimentar una nueva forma de trabajar, una nueva forma de pensar en el desarrollo de software. No se trata de reemplazar a los desarrolladores, sino de potenciarlos, de liberarles la mente para que puedan enfocarse en lo que realmente importa: la creatividad, la innovación, la resolución de problemas complejos.
La IA Generativa es una herramienta poderosa, pero necesita de un humano para guiarla, para corregirla, para mejorarla. Y eso es algo que me encanta de esta experiencia, el hecho de que haya un humano detrás de cada línea de código que se genera, y que ese humano tenga la capacidad de aprender, de evolucionar, de mejorar.
No se trata de dejar que la IA haga todo, sino de aprender a trabajar junto con ella, de aprovechar su poder para hacer más, para ser más, para lograr cosas que antes parecían imposibles.
Espero que esta experiencia les sirva de inspiración para explorar nuevas formas de trabajar, de pensar, de crear. Y que también les recuerde que el futuro no es algo que nos pasa a nosotros, sino algo que construimos juntos, con herramientas, con tecnología, con IA, con humanidad.
Finalmente, quiero decirles a todos aquellos que siempre quisieron desarrollar aplicaciones pero no pudieron que ahora es el momento, a partir de ahora nada es imposible, eso sí, no hay que entrar a éste proceso ingenuamente, hay que hacerlo con fundamentos por lo tanto a estudiar se dijo.
Gracias por leer hasta aquí, y como siempre, ¡hasta la próxima!
Enlaces
Sitio: https://registry.cloud.org.bo
Repositorios:
- API: https://github.com/awscbba/registry-api
- FrontEnd: https://github.com/awscbba/registry-frontend
- Infrastructura: https://github.com/awscbba/registry-infrastructure
- Documentación: https://github.com/awscbba/registry-documentation

